From Rebuilding Authentication in Every App to a Shared Identity Layer
This is the one where I finally stopped rebuilding login systems from scratch. Every single project. Every single time. JWT auth, refresh tokens, OAuth integrations, protected routes, role handling, session management — the same infrastructure problem, copy-pasted across my entire ecosystem.
Sound familiar?
Short take: Authentication is infrastructure, not a feature. Once you treat it that way, everything changes.

TL;DR
I stopped implementing authentication inside individual applications and started treating identity as shared infrastructure. The result: a centralized identity layer that handles federation, OAuth providers, and user management — while individual applications retain control over their own roles and authorization.
The shift wasn’t a rewrite. It wasn’t a giant enterprise IAM platform. It was a gradual architectural evolution that eliminated an entire category of repeated engineering work from future projects.
The hard parts weren’t OAuth. They were identity consistency, email normalization, token boundaries, and understanding the difference between authentication and authorization.
Identity and authorization are not the same system. That distinction saved me from a world of complexity.
The Breaking Point
Most developers hit this eventually. You build your first application. Auth feels simple. You wire up JWT authentication, add refresh tokens, protect your API routes, handle session state on the frontend. It’s straightforward. One application, one auth system, one set of rules. You’re in control.
Then the second app arrives. You copy the auth logic over, maybe tweak a few things, but the core pattern is the same. No big deal.
Then the third app arrives. And that’s when you start noticing something uncomfortable.
Every project ends up with slightly different auth logic. One app handles token refresh in a middleware, another does it in a service layer. One frontend stores sessions in localStorage, another uses httpOnly cookies. OAuth integrations drift over time because each project updates on its own schedule. User management becomes fragmented — some users exist in one app but not another, and there’s no single source of truth.
And when you need to fix a bug in the auth logic? You fix it in one place, then realize you need to apply the same fix everywhere. Three apps means three fixes. Three tests. Three deployments.
The real cost isn’t the initial implementation.
It’s the long-term duplication.
I was rebuilding the same infrastructure problem over and over again. Not because authentication itself is impossible — because identity becomes complicated once multiple applications, providers, roles, and users start interacting.
The Math That Made Me Stop
Let’s do some quick math. Three applications, each with JWT authentication, refresh tokens, and OAuth support through GitHub and Google. Each with slightly different session handling because the frontends were built at different times. Each with their own user management because there was never a reason to share users across apps.
That’s essentially the same codebase maintained in three places. Three sets of bugs. Three sets of security patches. Three times the work for the same result.
And that’s just three apps. Imagine five. Imagine ten. The multiplication doesn’t slow down — it accelerates.
The Architectural Shift
The key realization was this:
Authentication is infrastructure.
Not just an application feature. That distinction changes how you think about systems.
When authentication is a feature, each application owns its own login flow, its own session management, its own user records. That works fine for a single app. But the moment you have multiple applications serving the same users, you’ve got a coordination problem.
Instead of thinking “each application owns authentication,” the architecture shifts to “applications consume a shared identity layer.” That’s not just a philosophical change — it’s a structural one. It means the identity layer becomes a service that other applications depend on, not a feature that each application builds independently.
That shift immediately changes how you approach maintenance, onboarding, OAuth integrations, SSO support, user consistency, and development velocity. When a new OAuth provider needs to be added, you add it once. When a security patch is needed, you patch once. When a new developer joins the team, they learn one auth system instead of three variations of the same concept.
Short take: Stop thinking “how should this app implement auth?” Start thinking “how should this ecosystem handle identity?”
Hybrid Authentication: The Practical Approach
One important design choice was avoiding a full migration. I did not want to break existing users, force rewrites, destroy working auth systems, or centralize everything prematurely. Those are the kinds of decisions that seem bold in planning meetings but turn into operational nightmares in production.
Let’s be real: nobody wants to hear “we’re rewriting authentication” when the current system works. That’s how you introduce bugs and lose user trust. Users don’t care about your architecture — they care about logging in and getting their work done. If you break that, you’ve failed.
So the system evolved into a hybrid model. Applications still support local email/password auth for users who prefer it or for legacy integrations that expect it. But they can also support centralized login, OAuth providers, and federated identity through the shared layer.
This ended up being significantly more practical than attempting a complete replacement architecture upfront. It let existing users continue working without interruption while new users could adopt the centralized approach immediately.
War Story — The Migration That Wasn’t
I originally planned a full migration strategy. Rip out per-app auth, replace with centralized identity, done. Clean, decisive, architecturally pure.
Then I realized that meant forcing password resets for every existing user, breaking active sessions across all applications, rewriting frontend auth logic in multiple codebases, and testing everything simultaneously while keeping the old system running as a fallback.
That’s not a migration. That’s a hostage situation.
The hybrid approach let me deploy the identity layer alongside existing auth, gradually migrate applications one by one, keep existing users authenticated throughout the process, and learn from each migration before doing the next. Each application migration became a small, reversible experiment rather than a high-stakes all-or-nothing gamble.
The Hard Part Wasn’t OAuth
The difficult part was identity consistency. The happy-path OAuth demo always looks clean. User clicks “Login with Google,” gets redirected, authenticates, gets redirected back with a token, you create a session, done. Six steps. Looks simple in a tutorial.
Reality is different. Every single time.
Problem #1 — Missing Identity Claims
One of the first issues encountered was a successful login flow that still failed user creation. Authentication succeeded — the OAuth provider confirmed the user’s identity and returned a valid token. But the application rejected the session because critical identity data was missing from the token payload. The user was authenticated, but the application didn’t have enough information to actually create a usable account.
Successful authentication does not automatically mean you received a usable identity profile.
Identity claims matter. You need the email address to create the user record. You need the email verification status to know whether to trust the account. You need profile mapping information to populate the user’s display name and avatar. You need provider consistency to link accounts across different OAuth providers.
Without those claims, federation becomes unreliable very quickly. You end up with users who can authenticate but can’t actually use your application — a frustrating experience that looks like a bug but is really an architecture gap.
War Story — The Phantom Login
I spent three hours debugging a “phantom login” — the OAuth flow completed successfully, Google returned a valid token, but the user never actually got logged in. The redirect happened, the token was received, and then… nothing. No session created. No redirect to the dashboard. Just a blank stare at the login page.
The culprit? The identity provider returned the email claim, but my application expected the email and email_verified claim. Without that second claim, the user creation logic silently failed. Not with an error — with nothing. The code path that should have created the user simply didn’t execute because a conditional check failed.
I was checking logs for auth failures. The auth succeeded. The failure was in the identity mapping layer — a completely different part of the system that I wasn’t looking at because I assumed the problem was in the OAuth flow itself.
Problem #2 — Existing User Linking
Another issue appeared when testing with existing application users. A user who already had an account in the application tried to log in through the centralized identity layer for the first time. The identity provider authenticated correctly — GitHub confirmed their identity, the token was valid, everything looked good on the surface. But the application authorization layer did not preserve existing permissions.
The user logged in through GitHub and suddenly had a different role than they had before. Their existing projects, their settings, their permissions — all gone. Not deleted, just inaccessible because the new login created a new authorization context that didn’t know about the old one.
Identity and authorization are not the same system.
Eventually the architecture stabilized around this rule: centralized identity handles authentication (who are you?), and individual applications retain authority over roles and permissions (what can you do?). That separation ended up preventing a lot of future complexity.
Why This Distinction Matters
Think about it. Authentication answers the question “who are you?” — the identity layer handles this by verifying credentials and returning identity claims. Authorization answers the question “what can you do?” — the application handles this by checking roles, permissions, and access control rules.
If you mix these, you end up with centralized systems that need to know about every application’s roles (which means the identity layer has to be updated every time any application changes its permissions), applications that can’t evolve their permission models independently (because they’re coupled to a centralized authorization engine), and a tangled mess that nobody wants to maintain because changing one thing breaks three other things.
Keep them separate. Your future self will thank you.
Problem #3 — Email Normalization
This was one of the most subtle bugs I’ve encountered in years of building software. Different systems handled email casing differently. Some providers return emails in lowercase, some preserve the original casing, some normalize differently depending on the authentication method. The result was inconsistency across the system.
Consider this:
[email protected]
[email protected]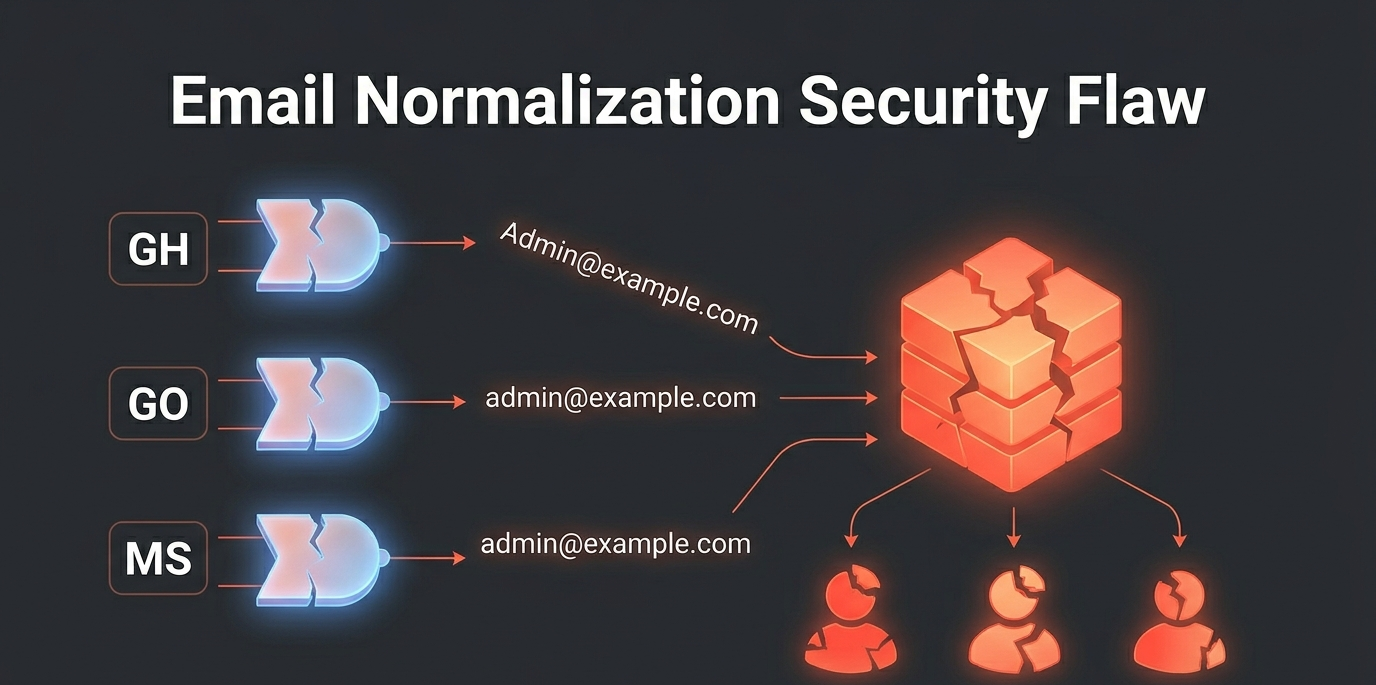
These look like the same email address to a human. But to a database, they’re different strings. Different identity records. Same human.
That caused duplicate account creation during federation flows. A user who signed up with GitHub (which returned [email protected]) and then tried to log in with Google (which returned [email protected]) ended up with two separate accounts. Same email. Same person. Two identities.
The solution was straightforward in hindsight: normalize emails everywhere. Lowercase before persistence, lowercase before comparison, lowercase during account linking. Every email that enters the system gets converted to lowercase before it touches the database.
Simple bug. Very real consequences.
War Story — The Duplicate Accounts
I discovered this bug when a test user created accounts through three different OAuth providers — GitHub, Google, and Microsoft. Three separate identity records. Same email address. Three different accounts.
The user then complained they couldn’t see their projects across “different accounts.” They weren’t different accounts. They were three records of the same person because one system stored [email protected] and another stored [email protected]. The projects existed in one account but not the other two, and the user had no way to merge them.
The fix took fifteen minutes. The cleanup of the test data took an hour. The real lesson — that email normalization needs to happen at the infrastructure level, not at the application level — took much longer to fully internalize.
Problem #4 — Token Boundaries
Another important lesson involved token handling. Initially, upstream identity provider tokens were exposed unnecessarily to the frontend layer. The Google access token, the GitHub token, the refresh tokens for each provider — all of it was available in the browser’s JavaScript context.
That was quickly corrected once I realized the security implications.
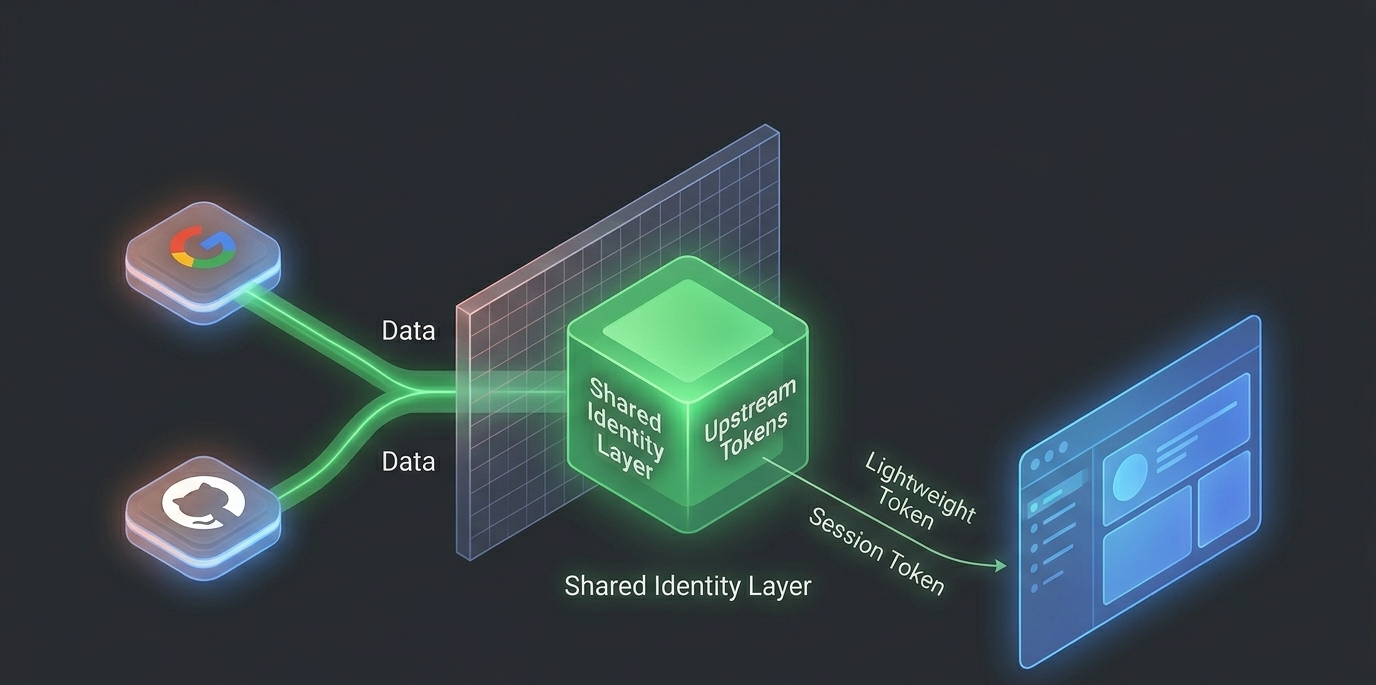
The improved architecture became:
Identity Provider → Application Auth Layer → Application Session → Frontend
The frontend only needs the application session. It needs to know whether the user is authenticated and what they can do. It does not need direct access to upstream federation tokens — those are the identity layer’s concern, not the frontend’s.
That separation significantly improves security posture while also simplifying the frontend. The frontend becomes a consumer of authentication state, not a manager of authentication credentials.
Why Token Boundaries Matter
Upstream tokens from providers like Google and GitHub have their own expiration logic, their own refresh mechanisms, their own scope limitations, and their own security considerations. They’re complex, they’re provider-specific, and they change over time as providers update their APIs.
Exposing these to the frontend means managing multiple token lifecycles in JavaScript, handling upstream refresh logic in the browser, risking token leakage through XSS vulnerabilities, and creating tight coupling between your frontend and upstream providers. Every time Google changes their token format or GitHub updates their scope handling, your frontend code needs to change too.
Keep upstream tokens server-side. Your frontend only needs to know if the user is authenticated and what they can do. Let the identity layer handle the complexity of upstream token management.
The Ownership Table
The architecture only became stable once ownership boundaries were explicit. Every piece of the authentication and authorization puzzle needed a clear owner — someone responsible for it, someone who could change it without breaking everything else.
| Responsibility | Ownership |
|---|---|
| Identity federation | Centralized identity layer |
| OAuth providers | Identity layer |
| Application roles | Individual applications |
| Authorization | Individual applications |
| Sessions | Application auth layer |
| UI auth state | Frontend |
Without clear boundaries, auth systems become extremely difficult to reason about. When something breaks, you need to know where to look. When something needs to change, you need to know who owns it. When a new feature is requested, you need to know which layer it belongs in.
Avoiding Premature Complexity
One thing I intentionally avoided was immediately turning this into a giant auth microservice platform, a distributed authorization mesh, or a fully centralized permission engine.
That would have been premature. Those are solutions looking for problems — impressive architectures that solve scaling challenges I didn’t have yet.
The architecture evolved from solving recurring operational pain first. Every design decision was justified by a real problem I’d encountered, not a hypothetical scenario I’d read about in a blog post. Only after patterns became obvious did the shared identity layer become worthwhile.
That order matters. A lot.
What I Didn’t Build (And Why)
| Temptation | Why I Resisted |
|---|---|
| Full microservice auth platform | Overkill for 3-5 applications |
| Centralized RBAC engine | Applications have different permission models |
| Custom OAuth provider | Too much surface area for bugs |
| Event-driven auth pipeline | Added complexity without solving current pain |
The full microservice auth platform would have required its own infrastructure, its own deployment pipeline, its own monitoring, and its own team to maintain. For three to five applications, that’s not engineering — that’s resume-driven development.
The centralized RBAC engine assumes all applications share the same permission model. They don’t. One application might have a simple admin/user split, while another needs granular permissions for different resource types. Forcing them into the same RBAC framework would have required either compromising one application’s needs or building an increasingly complex permission engine.
The custom OAuth provider sounds appealing until you realize you’re now responsible for implementing OAuth correctly, handling token exchange securely, managing provider certificates, and keeping up with security patches. That’s a full-time job, not a side project.
The event-driven auth pipeline is architecturally elegant but solves a coordination problem I don’t have. My applications don’t need to react to authentication events in real-time — they just need to verify sessions and check permissions.
The Cohesive Ecosystem Experience
One of the goals of this architecture was ensuring that authentication felt like part of the ecosystem itself rather than a disconnected third-party experience.
As the shared identity layer evolved, additional work was done around the user experience. Custom branded authentication interfaces replaced generic OAuth login pages. Consistent login UX across services meant users didn’t feel like they were entering a different system when switching between applications. Unified session flows meant the login and logout experience was predictable everywhere. Shared visual identity between applications reinforced that these were part of the same platform, not separate products.
This helped transform authentication from “separate login systems per application” into “one cohesive ecosystem experience.”
Why This Matters
When a user logs into one application and then visits another, they shouldn’t feel like they’re entering a different system. The login page should look the same. The error messages should be consistent. The password reset flow should work identically. The session timeout behavior should match.
Consistent authentication means the same login page design across all apps, the same session behavior, the same error messages, and the same password reset flow. It’s the difference between “these are separate products” and “this is a platform.”
That distinction matters for user trust. When authentication looks and feels different across applications, users start wondering whether their data is safe. When it’s consistent, they stop thinking about authentication entirely — which is exactly the point.
Multi-Provider Federation
The identity layer was also designed to support multiple external identity providers through federation. GitHub for developers who prefer it, Google for general users, Microsoft for enterprise environments, Facebook for broader accessibility, and additional OAuth/OIDC providers over time as user demand evolves.
This allows applications inside the ecosystem to avoid implementing provider integrations individually. Instead of each application maintaining its own GitHub OAuth configuration, its own Google client ID, its own Microsoft integration — the identity layer handles all of that once, and every application inherits it automatically.
When a new provider needs to be added, you add it to the identity layer. Every application in the ecosystem immediately gains support for that provider without any code changes. That’s the power of centralized infrastructure.
The Provider Integration Benefit
Before centralized identity, each application implemented its own OAuth integrations. App A implements GitHub OAuth with one set of configuration. App B implements GitHub OAuth with a slightly different approach — maybe it handles the callback differently, or stores the token in a different format. App C implements yet another variation because it was built by a different developer at a different time.
Each one needs separate client IDs, separate secrets, separate callback URLs. Each one handles token exchange differently. Each one has its own bug fixes and edge cases. When GitHub updates their API, you need to update three codebases instead of one.
After centralized identity, the identity layer implements GitHub OAuth once. All applications inherit it automatically. Same client ID, same secret, same callback URL. Same token exchange logic. Same bug fixes. When GitHub updates their API, you update one codebase.
Short take: Implement once, use everywhere. That’s the whole point.
The Bigger Shift
The interesting thing about this process is that it changes how you think about applications entirely.
“How should this app implement auth?”
Eventually you stop asking that and start asking:
“How should this ecosystem handle identity?”
That is a completely different architectural mindset. It moves you from thinking about individual applications to thinking about platforms. From building features to building infrastructure. From solving today’s problem to preventing tomorrow’s duplication.
From Feature to Infrastructure
| Before | After |
|---|---|
| Auth is a feature in each app | Auth is infrastructure shared across apps |
| Each app owns its users | Users exist in the identity layer |
| OAuth integration per app | OAuth integration once, inherited by all |
| Sessions are app-specific | Sessions follow a consistent pattern |
| Bug fixes repeated everywhere | Bug fixes happen once |
This shift compounds over time. The more applications you add, the more value the centralized approach provides. The first application doesn’t benefit much — you’ve built infrastructure for one app. The second application benefits moderately — you’re reusing existing infrastructure. By the fifth application, you’re saving weeks of development time per project because the authentication infrastructure already exists and just works.
That’s the real return on investment. Not the initial build — the compounding reuse.
Final Thoughts
Most developers interact with authentication constantly. Far fewer end up designing identity systems as infrastructure.
Once multiple applications, OAuth providers, roles, and users begin interacting, authentication stops being a simple login form problem and becomes a systems design problem. It’s about ownership boundaries, about separation of concerns, about building for reuse without premature abstraction.
And honestly, that was the biggest takeaway from this entire process.
The real win was not adding SSO. It was eliminating an entire category of repeated engineering work from future projects.
The best authentication system is the one you don’t have to build in every new project.
What’s Next
The identity layer continues to evolve. Fine-grained permission federation is next — the ability to define permissions at the identity layer level for applications that want to share authorization logic, while still allowing applications to maintain their own permission models when needed.
Audit logging across applications will provide visibility into who accessed what and when, which is essential for security and compliance. Multi-factor authentication support will add another layer of security for users who want it. Device management and session revocation will give users control over where they’re logged in.
But the core principle remains: authentication is infrastructure, not a feature.
Build it once. Build it right. Let every application in your ecosystem benefit.
NemesisNet Hub Links
Related Reading
- ForkMyFolio Backend: Multi-User Portfolio Platform — See how we implemented JWT auth with refresh cookies in a Spring Boot app
- VibeType: Local-First Voice Coding Companion — Uses MCP server for agent automation with local-first auth
- Self-Hosted CI/CD on a Home Rack — How we deploy everything with zero cloud CI costs